앞에서 정리한 것처럼, 프로그래밍 언어는 일정한 문법적 구조를 가지고 있다.
BNF는 그런 구조를 명확하게 정의하기 위한 도구이다. (문장을 만들어낼 수도 있고, 주어진 문장이 그 문법에 맞는지 판별할 수도 있음)
Preliminaries
Terminal & Nonterminal
| 구분 | 설명 | 예시 |
|---|---|---|
| Terminal | 더 이상 변하지 않고 실제 코드에서 보이는 기호 | =, +, if, 0 |
| Nonterminal | 다른 규칙으로 대체 가능한 기호 (문법 구조를 추상적으로 표현) | <expr>, <stmt>, <assign> |
Chomsky hierarchy
Context-free and regular grammars are useful for programming languages
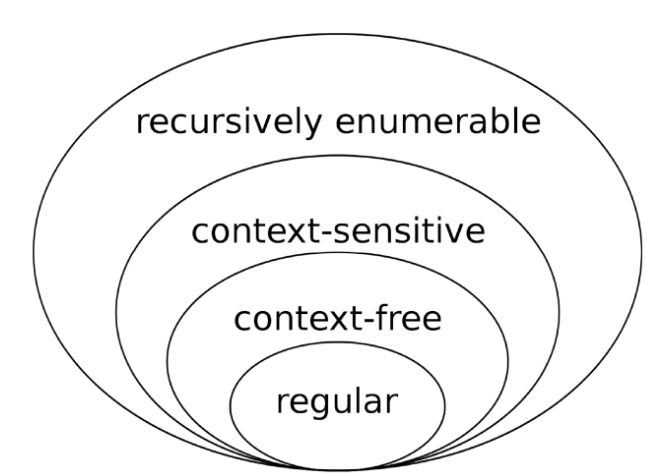
- Recursively Enumerable
- 가장 일반적인 문법으로, 어떤 제약도 없이 모든 형태의 생산 규칙을 허용
- Context-Sensitive
- 생산 규칙의 왼쪽에 비터미널 외에도 추가적인 기호(문맥)가 포함될 수 있음
- Context-Free Grammar (CFG)
- 프로그래밍 언어 대부분의 구문 분석은 이 CFG 기반
- 각 규칙은 단일 비터미널로 시작
- 문맥을 고려하지 않음
- 복잡한 중첩 및 재귀 구조를 표현 가능
- Regular Grammar
- 가장 단순함
- 어휘 분석(토큰화)에 사용
프로그래밍 언어의 대부분은 CFG 수준의 복잡성을 가진다.
BNF는 CFG를 기반으로 만들어진다.
Backus-Naur-Form
BNF의 기본 구조
BNF는 프로그래밍 언어의 구문을 형식적으로 정의하는 메타언어이다.
구문 구조에 대한 추상화적 표현
LHS(Left-hand side) → RHS(Right-hand side)
- LHS: 하나의 nonterminal
- RHS: tokens, lexemes, other abstractions(nonterminal)가 조합
<assign> → <var> = <expression>
- LHS:
<assign>(할당문)이라는 추상 개념 - RHS: 추상화가 어떻게 구성되는지를 설명, 다른 추상화(
<var>,<expression>)와 터미널(=, 연산자 토큰)의 조합
Production Rule
Method that generates sentences using nonterminal and terminal symbols.
문법은 여러 개의 규칙(Rule)으로 정의됨.
규칙은 다음과 같이 여러 가지 선택지를 | 기호로 표현할 수 있다.
<if_stmt> → if (<logic_expr>) <stmt>
| if (<logic_expr>) <stmt> else <stmt>위 규칙은 else가 있는 if문과 없는 if문을 모두 허용한다.
Start Symbol
문법(BNF)은 항상 특정 nonterminal에서 시작해야 한다.
<program> (<start>인 경우도 있음)에서 시작.
<program> → begin <stmt_list> endRecursion
When LHS appears in RHS
BNF에서 어떤 nonterminal이 자기 자신을 우변에 포함하면 Recursion(재귀)이다.
재귀를 통해 반복적인 구조나 리스트 구조(Variable-length Lists)를 표현할 수 있다.
<array> → element
| element, <array>Derivation
Derivation(파생)은 문법 규칙을 하나씩 적용해가며 nonterminal을 terminal로 바꾸는 과정이다.
Leftmost Derivation / Rightmost Derivation
- Leftmost Derivation(왼쪽 파생)
- 항상 가장 왼쪽의 넌터미널부터 규칙을 적용 (치환)
- Rightmost Derivation(오른쪽 파생)
- 항상 가장 오른쪽의 넌터미널부터 규칙을 적용
<program> → begin <stmt_list> end
<stmt_list> → <stmt> ; <stmt_list> | <stmt>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var>
| <var> - <var>
| <var><program>
=> begin <stmt_list> end
=> begin <stmt> ; <stmt_list> end
=> begin <stmt> ; <var> = <expression> end
=> begin <stmt> ; <var> = <var> - ‹var> end
=> begin <stmt> ; <var> = ‹var> - A end
=> begin <stmt> ; <var> = C - A end
=> begin <stmt> ; B = C - A end
=> begin <var> = <expression> ; B = C - A end
=> begin <var> = <var> + <var> ; B = C - A end
=> begin <var> = <var> + C ; B = C - A end
=> begin <var> = B + C; B = C - A end
=> begin A = B + C; B = C - A end위 예시는 Rightmost derivations.
문법에 맞지 않는 문장 예시
A = B + C: 반드시 begin으로 시작하고 end로 끝나야 함
begin A = B * C end: 곱셈 기호는 정의되어 있지 않음
begin A = B + C ; D = A end:<var>는 오직 A, B, C 중 하나로 정의되어 있음
begin A = B + end: + 뒤에<var>가 없음
Parse Tree
Statement를 계층적으로 시각화한 트리 구조.
BNF 규칙을 하나씩 적용하면서 어떤 순서로 문장이 구성되었는지 보여줌.
| 구성 요소 | 역할 |
|---|---|
| 내부 노드 | 넌터미널(nonterminal) |
| 리프 노드 | 터미널(terminal) |
| 서브트리 | 문법 규칙에서 하나의 추상 개념을 구성하는 단위 |
BNF 규칙이 아래와 같을 때:
<assign> → <id> = <expr>
<expr> → <id> + <expr> | <id>
<id> → A | B | C아래 Parse Tree는 A = B + C가 어떤 방식으로 구성되었는지를 계층적으로 보여준다.
<assign>
|
<id> = <expr>
| \
A <id> + <expr>
| |
<id> <id>
B C
Ambiguity
Ambiguity(모호성)은 하나의 Statement가 여러 개의 Parse Tree로 해석될 수 있는 경우를 말한다.
(= 하나의 문법이 하나의 문장에 대해 여러 해석을 허용함)
<assign> → <id> = <expr>
<expr> → <expr> + <expr>
| <expr> * <expr>
| (<expr>)
| <id>
<id> → A | B | C위의 BNF에 대해
Statement A = B * C + D는
아래 두 개의 해석이 가능하다.
가능한 해석 1: A = (B * C) + D (multiply first)
<assign>
|
<id> = <expr>
/ \
A <expr> + <expr>
/ \
<expr> * <expr> <id>
/ \ |
<id> <id> D
B C가능한 해석 2: A = B * (C + D) (add first)
<assign>
|
<id> = <expr>
/ \
A <expr> * <expr>
/ \
<id> <expr> + <expr>
B / \
<id> <id>
C D우선순위가 결합 순서가 명확하지 않아서 모호성이 발생함.
Operator Precedence
위에서 살펴본 Ambiguity 해결을 위해 Operator Precedence(연산자 우선순위)를 정할 수 있다.
아래와 같은 BNF에서 A + B * C는 A + (B * C)로 명확하게 해석된다.
<assign> → <id> = <expr>
<expr> → <expr> + <term>
| <term>
<term> → <term> * <factor>
| <factor>
<factor> → ( <expr> )
| <id>Note
<expr>에서 덧셈 수식을 처리하고<term>에서 곱셈 수식을 처리하고, 우선 순위상<term>이<expr>보다 깊은 단계이기 때문에 우선순위가 정해진다.
Associativity
Parentheses가 없는 같은 우선순위의 연산자들 중 무엇을 먼저 연산할지를 정의한 것이 Associativity(결합법칙)이다.
| 종류 | 해석 방식 | 예시 |
|---|---|---|
| Left Associative (좌결합) | 왼쪽부터 묶음 | (1 + 2) + 3 |
| Right Associative (우결합) | 오른쪽부터 묶음 | 1 + (2 + 3) |
Left Associative를 원하면 Left Recursive(자기 자신이 연산자의 왼쪽) 를, Right Associative를 원하면 Right Recursive를 사용한다.
사칙연산과 같이 대부분의 경우는 Left Associativity.
<expr> → <expr> + <term> | <term>Right Associativity가 필요한 경우도 있다.
대표적인 예시로 Exponentiation(거듭제곱), Assignment(할당) Operator 등이 있다.
<factor> → <exp> "**" <factor> | <exp>Dangling Else Problem
<stmt> → if <logic_expr> then <stmt>
| if <logic_expr> then <stmt> else <stmt>
| ...위의 BNF에 대해
Statement if E1 then if E2 then S1 else S2를
if E1 then (if E2 then S1 else S2)나
if E1 then (if E2 then S1) else S2의 두 가지 Parse Tree로 해석할 수 있는 문제, else가 어떤 if에 속하는 지의 Ambiguity가 Dangling Else Problem이다.
Dangling Else Problem은
if-else의 쌍이 맞는 것(matched, 대응)와 맞지 않는 것(unmatched, 미대응)을 다르게 정의하는 방식으로 해결할 수 있다.
<stmt> → <matched> | <unmatched>
<matched> → if <logic_expr> then <matched> else <matched>
| <other_stmt>
<unmatched> → if <logic_expr> then <stmt>
| if <logic_expr> then <matched> else <unmatched>
이렇게 정의할 경우 else는 항상 가장 가까운 if에 자동으로 연결된다.
Extended BNF
BNF는 강력하지만 표현이 너무 장황하고 반복적이여서 반복, 옵션 등을 표현할 때 복잡하고 길어진다는 단점이 있다.
Extended BNF 줄여서 EBNF 는 아래 문법을 통해 BNF 문법을 간결하게 사용할 수 있게 한다.
| 기호 | 의미 | 예시 | 해석 |
|---|---|---|---|
| [ … ] | 선택사항 (옵션) | [else | 있어도 되고 없어도 됨 |
| { … } | 0번 이상 반복 | {+ | 여러 번 나올 수 있음 (또는 안 나올 수도 있음) |
| (…) | 그룹핑 | ( | 괄호로 묶어서 우선 순위 지정 |
<expr> → <expr> + <term>
| <expr> - <term>
| <term>위와 같은 BNF는 EBNF로 아래처럼 한 줄로 나타낼 수 있다.
<expr> → <term> { (+ | -) <term> }Right Associativity(우결합)은 EBNF에서 아래처럼 나타낼 수 있다.
<factor> ::= <exp> [ "**" <factor> ]